Road 2 NLP- Word Embedding词向量(FastText)
1. 参考资料
- 论文1:FastText1词向量,《Enriching Word Vectors with Subword Information》,作者Bojanowski et al. (包括Mikolov),FAIR(Facebook AI Research)
- 论文2:FastText2文本分类模型,《Bag of Tricks for Efficient Text Classification》,作者Joulin et al. (包括Mikolov),FAIR(Facebook AI Research)
- 博客文:《fastText 源码分析》
- FastText源代码(C++)
主要参考资料如上,其实还有其他博客文,然而很多博客文都是互相抄袭的……而且很多都是讲解FastText文本分类模型,而非FastText词向量,前者基于后者建模。FastText文本分类模型原理简单易懂,然而词向量的训练原理有某些地方讲的很含糊。基于以上参考资料,我只能做出个人理解。(因为看源码看了很久,还是感觉没能解决我的核心疑惑……)
FastText其实是包括2个东西的:
FastText词向量(PS:和Word2vec、GloVe一样,FastText词向量也属于静态词向量),对应论文1
FastText文本分类模型,对应论文2
虽说本系列文章主题是:Word Embedding词向量,但是由于FastText特殊性,这里一起讲FastText文本分类模型。
FastText的最大优点:快速。
《Efficient estimation of word representations in vector space》摘要部分:
We can train fastText on more than one billion words in less than ten minutes using a standard multicore CPU, and classify half a million sentences among 312K classes in less than a minute.
2. FastText原理1:词向量训练
关于FastText词向量资料,原论文《Enriching Word Vectors with Subword Information》的原理部分提及得相当简略。
FastText词向量框架是基于Word2vec框架的,区别主要如下:
前者利用n-grams向量之和作为词向量(key point & 疑惑点)

即单词w对应1个n-grams集合(原论文为提取3-grams ~ 6-grams的所有子串),每个字串会有对应的向量,因此该单词w的词向量 = 所有n-grams字串向量求和。
关于n-grams,原论文有以下例子:

这里,以where为例,其对应的3-grams子串集合G={"<wh","whe","her","ere","re>","<where>"},其中每一个子串对应1个向量表示,则where词向量则为求和。同理对于中文,举例苏格拉底的3-grams子串集合G_1={"<苏格","苏格拉","格拉底","拉底>,"<苏格拉底>"}。
以上原理都不难理解,关键在于:原论文貌似没给出子串向量是如何获得!当然n-grams向量理应是训练得到,然而如何训练,网络结构如何,原论文没提及,只是说基于Word2vec架构。Word2vec原理如下文:
Road 2 NLP- Word Embedding词向量(Word2vec)
本人一直卡在如何训练n-grams子串向量这问题上。涉及资料主要是:博客文《fastText 源码分析》、FastText源代码(C++)。经过多次分析猜测(由于本人最后还是放弃通读C++源码…我看了挺久,但还是不知道如何训练n-grams子串获得向量的,只发现了如何获取子串string代码)。
FastText默认Skip-Gram模型,对比Word2vec的Skip-Gram模型,有以下个人理解(由于画图较为复杂,此处文字描述):
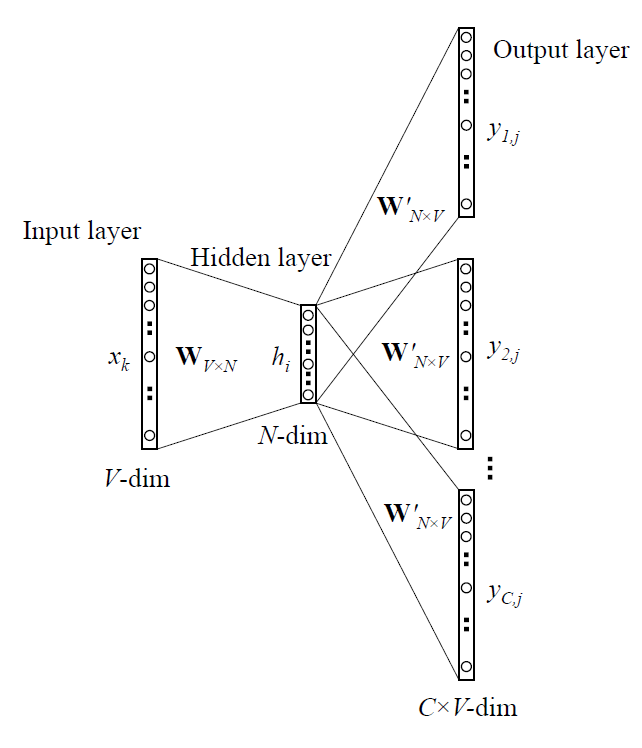
如上图为Word2vec原Skip-Gram模型。
- 输入层:输入为当前单词w的n-grams的index集合,从输入向量矩阵$W_{V×N}$中挑出对应n-grams向量求和,作为输入层的$x_{k}$。因此,FastText的输入层和Word2vec的区别在于:前者取n-gram求和作为词向量,后者取One-Hot词向量;前者输入向量矩阵$W_{V×N}$,其N为所有语料的n-grams总数,后者则为语料word总数。
- 隐含层&输出层:Word2vec & FastText一致。
因此,FastText词向量训练框架 & Word2vec不一致仅在于输入层。(PS:个人理解)
3. FastText原理2:文本分类模型
FastText文本分类模型和词向量训练框架差不多,有了词向量的原理基础,该模型可以很简单地用下图总结:
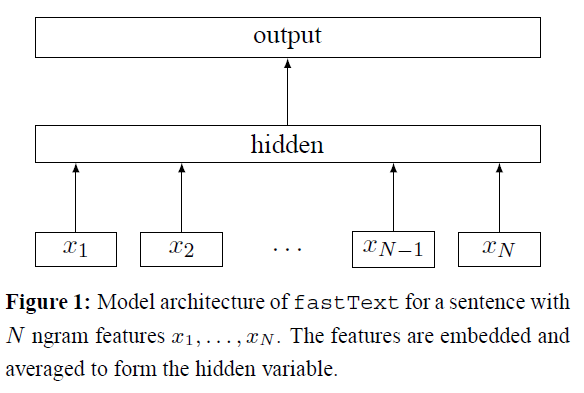
如上图,FastText文本分类模型仅3层。
- 输入层:句子的n-grams表示向量(PS:此处的n-grams向量为经过FastText词向量训练获得)
- 隐藏层:n-grams向量求平均(PS:FastText词向量训练则是求和)
- 输出层:softmax层(PS:沿用Word2vec的Hierarchical Softmax)
由此可以看出,关键是输入层的n-grams向量,而这个便是FastText词向量训练步骤。所以,FastText文本分类模型包括2步:1- FastText词向量训练;2- FastText文本分类模型构建。